先日、コンサルでお伺いした企業様より、Design Seriesについて「もう少しわかりやすいと助かる」との貴重なご意見をいただきました。
今回はその声にお応えし、前半はできる限りわかりやすく整理しつつ、後半では実務に必要な構造・ロジックにも踏み込みます。
00|「どれを選んだらいい?」からはじまる迷い

初めてAIを使い始めようとするとき、多くの人が「結局、どのAIを使えばいいの?」という疑問で立ち止まってしまいます。
最も安定した「基準」となる統合型LLM。文章作成から論理的な構造化、コード生成まで、あらゆるタスクにおいて高い次元でバランスが取れた推奨モデルです。
【実務上の注意】
システムが稼働していても、一時的に知能が著しく低下し、いつもの指示が突然通じなくなる、回答が支離滅裂になる、処理スピードが極端に遅くなるといった現象が発生することがあります。
圧倒的な「情報の塊(トークン数)」を処理できる統合型LLM。大量の書類や動画解析において、他のモデルを凌駕する強みを発揮します。
【2026年1月からの不安定さ】
非常に強力ですが、現在はUIのフリーズや送信ボタン(リターン)がクリックできない等の障害が頻発。また、重要な箇所を端折る「勝手な省略癖(要約癖)」や、同じ回答を繰り返す「思考の足踏み(ループ)」も観測されています。
プログラムのコード作成や正確な要約に特化した専門モデル。
【実務での制限】
ChatGPTやGeminiのような、ビジネス全般を網羅する統合型LLMではありません。特定の技術的アウトプットには高い精度を誇りますが、文章作成から実務全般まで幅広くカバーする汎用的なビジネス利用には適さない、プロ向けの特化型ツールです。
AI環境が極めて不安定な現在、特定のモデルに依存することは「業務停止」のリスクを伴います。ChatGPTとGeminiを常時並行して運用し、片方の不具合(フリーズや知能低下)を感じたら即座に切り替えられる体制を標準にしてください。
01|AIの利用形態は2つに分かれる

同じAI(GPTやGeminiなど)であっても、その「出口」によって、求められるスキルもコスト感覚も180度異なります。まずは自分がどちらの土俵に立っているかを正しく認識する必要があります。
ChatGPT (Plus / Team / Enterprise)
最も安定した「基準」となる統合型LLM。文章作成から論理的な構造化、コード生成まで、あらゆるタスクを高い次元でこなすメイン機です。月額固定料金(定額制)のため、コストを気にせず試行錯誤が可能です。
Gemini (Advanced / Business / Enterprise)
Google Workspace連携を前提とした統合型LLM。大量の資料読解や情報の統合処理に強いですが、2026年に入りUIのフリーズ等の不安定さが報告されており、バックアップ体制を整えて運用するのが賢明です。
Claude (Pro / Team)
正確な要約やプログラムコード作成に特化したプロ向けモデル。汎用的なビジネス利用全般には適しませんが、特定の難易度が高い専門業務において代替不可能な精度を発揮する「特化型」です。
GPT API (OpenAI)
【運用視点:利便性が極めて高い】 有料版と同様のチャット形式のテスト画面(Playground)がそのまま提供されています。エンジニアでなくても直感的にプロンプトの調整が行えるため、導入ハードルが最も低く、迅速な開発に適しています。
Gemini API (Google Cloud / AI Studio)
【運用視点:専門知識が不可欠】 Google Cloudの複雑な権限設定やコードベースの実装が前提です。エンジニアとしての基礎知識やITリテラシーがないと初期設定すら難しく、初心者には「使い勝手が悪い」と感じる壁が存在します。
Claude API (Anthropic)
【運用視点:開発者向け実験場が充実】 「Workbench」という専用ツールが優秀で、コードを書かずにブラウザ上で精緻なテストが可能です。GPTほど一般向けではありませんが、開発効率を重視したプロ向けの中間的な立ち位置です。
APIはいずれのモデルも月額固定ではありません。AIに送った文字数や画像、さらにAIが回答を導き出すために費やした「思考の量(トークン量)」に応じて、一文字単位で課金される完全従量制です。大量のドキュメント処理やプログラムによる自動実行を無計画に行うと、一ヶ月の利用料が個人の有料版を遥かに超え、数万〜数十万円単位に達するリスクが現実的に存在します。予算上限の設定など、厳密なコスト管理能力が不可欠です。
02|「同じことを聞いても答えが違う」という現実
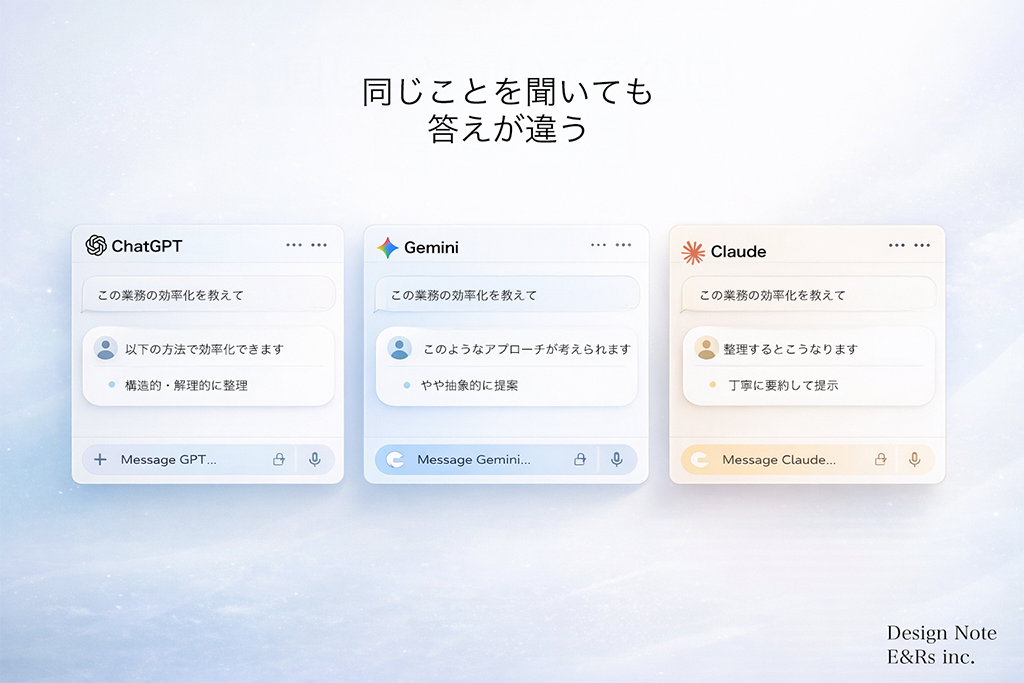
【モデル別】回答の切り口が明確に異なる

【回数別】同じモデルでも聞くたびに変化する
● AIは「固定された回答」を持っていない
検索エンジン(Google検索など)は、誰がいつ引いても同じ結果を返しますが、AIは根本的に仕組みが異なります。AIは過去のデータをそのまま返しているのではなく、あなたが投げかけた言葉に対して、その都度「次に続く確率が最も高い言葉」をリアルタイムで生成しているからです。
03|なぜ結果が変わるのか。原因は一つではない

AIごとに、学習に用いられた膨大なデータセットの構成や、開発メーカーによる調整方針が異なります。どの「知能の基盤」を選択するかによって、アウトプットの方向性は決定的に変わります。
汎用的な「統合型LLM」と、特定作業に特化したモデルでは、推論のプロセスが異なります。統合型は知識の広さを、特化型は論理の厳密さを優先するため、解決へのアプローチが大きく枝分かれします。
AIへの指示は「写真のピント合わせ」に似ています。背景情報や条件といった「指示の解像度」が低い場合、AIは不足分を確率的な推測で埋めます。この推測のゆらぎが、結果のバラつきを招く最大の要因です。
全世界的な負荷や調整により発生する「知能の一時的な低下(イエロー障害)」の最中には、本来のパフォーマンスが発揮できず、回答の論理性が著しく劣化します。昨日の「賢さ」が今日も維持されているとは限りません。
AIは「一度で正解を出すツール」ではなく、
条件を変えながら「最適解」を探り当てるプロセスそのものです。
04|AIはこう動いている:仕組みと「育てる」プロセス
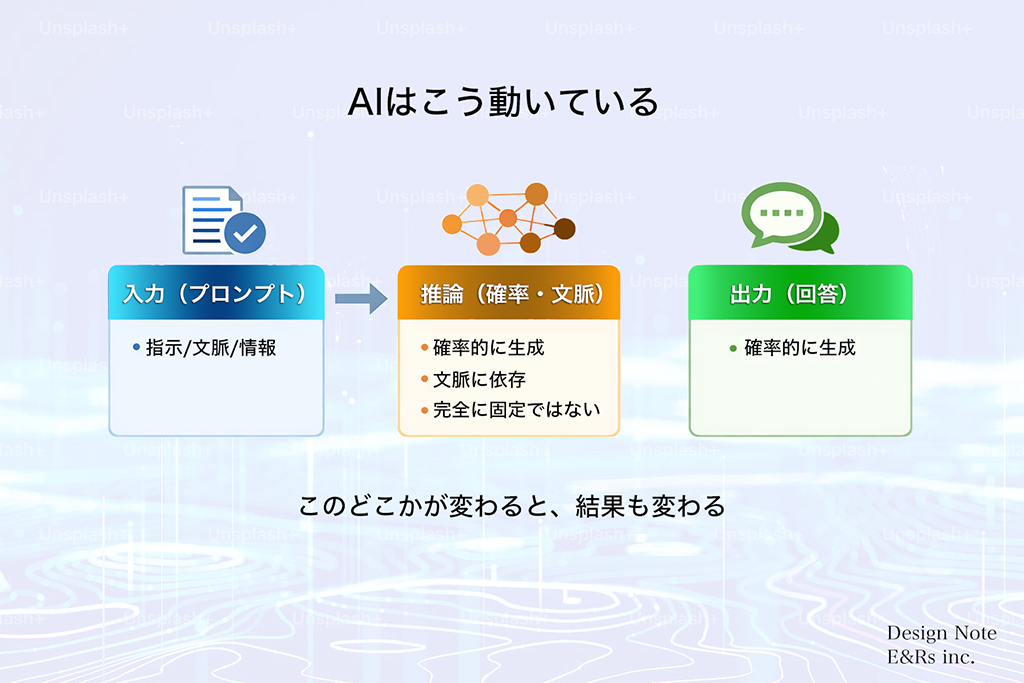
● 仕組みの全体像:AIは「固定された答え」を呼び出していない
検索エンジンとAIの決定的な違いは、この処理プロセスにあります。AIは内部に正解のデータベースを持たず、その都度「計算(推論)」によって回答を組み立てているのです。
言葉、文脈、添付資料を「情報の塊(トークン)」として受け取ります。ここでの具体性が低いと、AIは曖昧な部分を「推測」で埋めることになります。
文脈に依存し、「次に続くのが最も確率的に自然な言葉」を一文字ずつ計算します。この計算には常に「ゆらぎ」が含まれます。
推論の結果、最もありそうな言葉の連なりがリアルタイムで生成されます。それは「完成された真実」ではなく「確率の結果」です。
● 実務の核心:AIを「専用パートナー」に育てる
「確率で動く」仕組みを逆手に取り、回答を安定させる唯一の方法が情報の継続的な蓄積です。
自ら作成した仕様書(PDF)、設計図(イメージ)、あるいは過去のプログラム(ソースコード)などをAIに読み込ませ、共有し続けることが重要です。一朝一夕ではAIはあなたの業務の「癖」を理解しません。最低でも3ヶ月から半年間、一貫した情報を共有し続けることで、AI内部の推論精度は劇的に向上し、あなたの意図を先読みした安定的な回答が可能になります。
国内大手のSIerやシンクタンクが主導する大規模な現場ほど、過去の資料を安易に継ぎ接ぎした「上書き文化」が根深く定着しています。誰が何の意図で書いたのか不明なままコピペされ続けたドキュメントは、論理が崩壊した「死んだ情報」に過ぎません。
こうした出所の怪しい情報をいくらAIに読み込ませても、精度向上どころか、AIの推論を混乱させ、致命的な誤回答を招く原因となります。大手企業の看板や資料の体裁に惑わされないでください。
AIを賢くするのは、「自らの手で作成し、内容に全責任を持てる生きた情報」だけです。自らが監修した仕様書、自らが定義したコード。そうした純度の高い一次情報を、最低でも半年間積み上げること。この「情報の選別」へのこだわりこそが、AIを真のパートナーへと進化させる絶対条件です。
05|なぜ入力を固定すると安定するのか:ゆらぎを制する構造設計
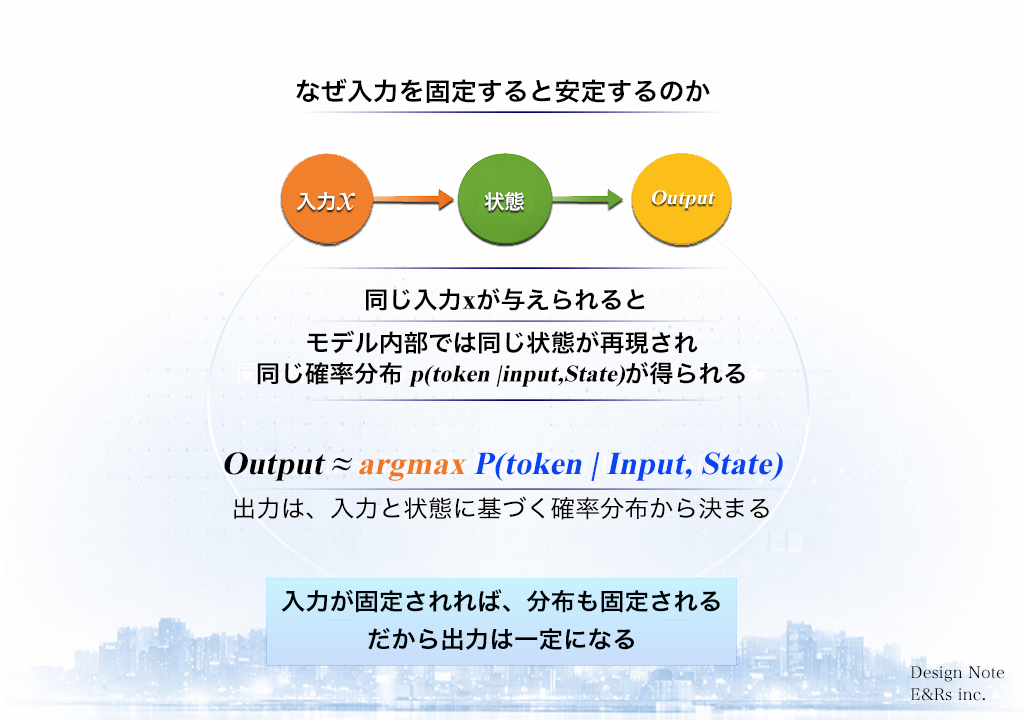
● 安定は「数理モデル」から導き出される
AIの出力が「時によって変わる」のは、気まぐれではなく「確率分布の制御不足」の結果です。プロフェッショナルな設計において、推論は以下の数式で定義されます。
Output
≈
argmax
P(token | Input, State)
「Input と State を構造化して固定し、確率を収束させる」。これが知能を実務レベルで統制するための数理的な必然です。
● 「型」ではなく「意味の分布」を固定する
AIの実務運用において、現在最も一般的な手法がRAG(Retrieval-Augmented Generation / 検索拡張生成)です。
しかし、4年間にわたりAIと「格闘」し続けてきた立場から言えば、単に情報を添えるだけのRAG実装には明確な構造的限界があります。
RAGはあくまで「外部情報を参考にする」仕組みであり、AIの「解釈のゆらぎ」そのものを抑え込むことはできません。検索した情報の断片化による文脈の喪失や、AIが都合よく情報を読み飛ばすハルシネーションのリスクを、既存のRAG構成で100%防ぐことは極めて困難です。
私たちが提唱するのは、情報の追加に留まらず、一次情報を推論の絶対的な基点(State)として構造化し、AIの「解釈の自由度」を数学的に制限する設計思想です。正解への確率を強制的に収束させる。この完全制御こそが、アーキテクトが担うべき真の介入領域です。
● 構造(Architecture)による強制力
安定性はAIにお願いして得られるものではありません。AIが他の言葉を選べないほどに論理的な外堀を埋める「構造」を設計して初めて、AIは実務に耐えうる「資産」へと昇華するのです。
※この「構造化による固定」は、AIを統制するための重要な基礎工程ですが、これだけで全てが解決するわけではありません。さらに深刻な「次のリスク」への備えが必要となります。
06|知能の連鎖汚染:情報の熱力学的崩壊とセマンティック・ハザード

● AI研究者の視点:アルゴリズムが内包する「不確実性」の連鎖
生成AIは本質的に確率的な自己回帰モデルです。出力は常に「最も確率的に自然なトークン列」に過ぎず、真実を返しているわけではありません。
単一モデルでは許容できた「ゆらぎ(ノイズ)」は、多段構成においてエントロピーの増大として顕在化します。前段の微細な誤差が次段では「確定した事実」として扱われ、推論の過程で指数関数的に増幅されます。
これは偶発ではなく、数理的必然としての知能崩壊です。
● セマンティックな密結合:分散設計が通用しない理由
通常の分散システムでは、AWSやAzure、複数LLMの併用によりSPOFは排除されます。しかしAI連携では、物理分離とは無関係に意味レベルでの密結合が発生します。
ノイズはプロトコル上「正常データ」として通過し、監視・検証をすべてバイパスします。その結果、GPTのハルシネーションはAPI経由で他モデル・他インフラへと即座に伝播します。
● なぜ検知できないのか
APIが200 OKを返す限り、知能の崩壊は検知できない。
型やチェックサムは「形式」しか見ない。「意味」は保証しない。
完璧な文章で誤りを出力するため、人間が異常を認識できない。
● カスケード・フェイルア(SN比崩壊)
一つのAIの誤差は、次のAIの入力となる瞬間に「前提」となります。
この連鎖によりSN比は指数的に悪化し、最終的には完全に論理的な虚偽が生成されます。
● FAILURE GUARD:物理レイヤーで遮断する
定期的にコンテキストを破棄し、純粋な状態から再構成。
異常検知時にAPI接続を物理的に遮断。
安定とは信頼ではない。
崩壊を前提に、構造で断ち切ること。
以上のことから、必要なのはAIエンジニアではない。
AIアーキテクトである。